
What do Medical Librarians tweet about? An extremely silly post.
Usually, when I do a conference recap, I wait a few days for the data to settle. However, we’ve got an earlier flight on Friday, and with a wedding and Mother’s Day this weekend, the data would be stale by the time I could reasonably get to it.
So what we do here is use Twitter’s API to pull all the tweets we could find with the hashtag #MLANET22. This yielded a database of 1,607 tweets as of the time I wrote this post.
Not bad! Let’s dive into the online discourse.
Frequent Words and Word Pairs
The most straightforward natural language processing method is bag-of-words. What BOW does is treat each unique word as meaningful in itself, and therefore words (or phrases) that occur frequently are “more meaningful.” The first thing we have to do is correct for stopwords, which are things like “the,” and “and,” that don’t add that much semantic meeting. Of course, reasonable people have discussions about what words should be stopwords, but that’s a conversation for another time.
So here are the most frequent terms! The Janet Doe lecture seems to be the most popular tweet string, and everything else aligns with what we would probably predict.
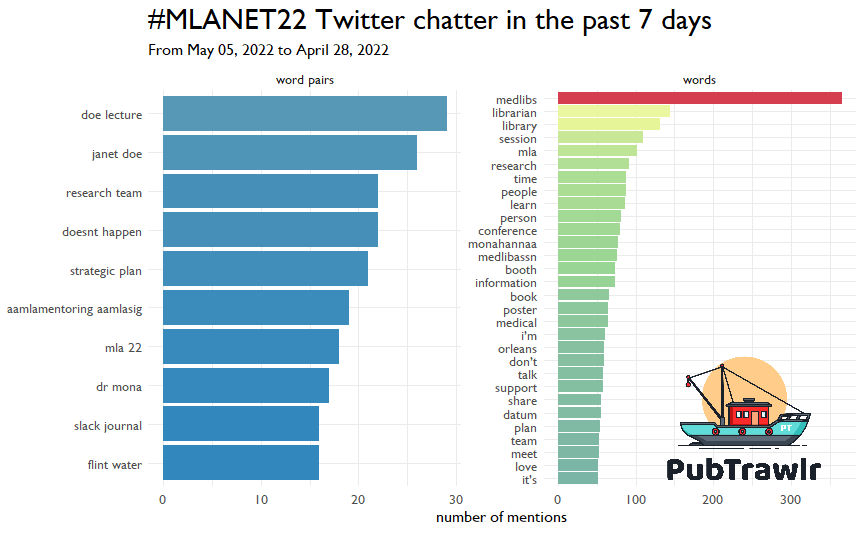
I also like to do network plots because they can capture strings longer than two words. This shows a bit more nuance than the bar graphs are able to do. We see many more names, things about the Flint Water Crisis (which is still going on), and other general conference happenings.

Sentiment Analysis
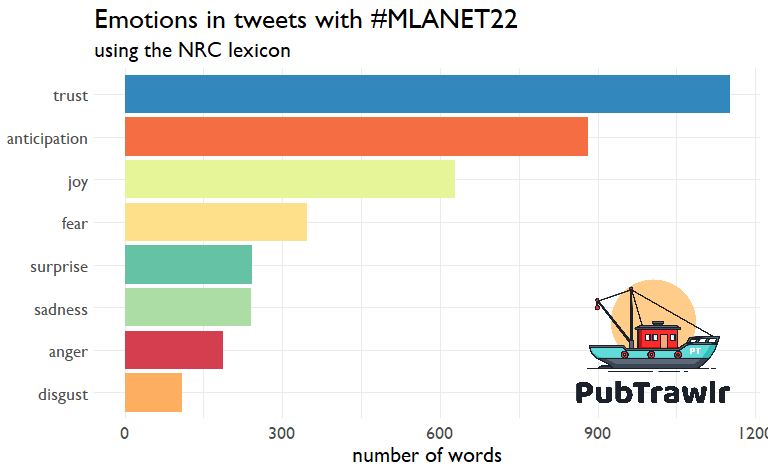
Let’s move on to another method: Sentiment Analysis. In sentiment analysis, we use a set of words associated with specific emotions. This is a very basic version of transfer learning. Here, we see that words are associated with trust and anticipation. Not a lot of disgust and anger. That’s a good thing! Probably because the people (and food) here have been freaking amazing.
Topic Modeling
Now, let’s see what tweets cluster together. We use a version of a latent Dirichlet allocation, which looks at how different words occur together across different tweets. Tweets around Monahanna occurred the most. Other topics are a bit harder to interpret. If I wasn’t writing this on 4 hours of sleep, I might try to tune the model a little more to collapse some of these categories and get some more distinct.
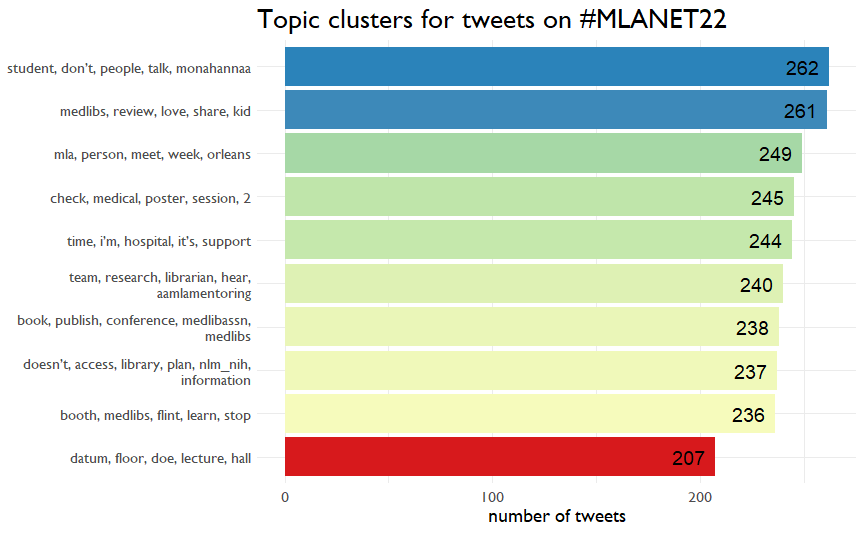
This is an essential point about AI in general. Data is just data. People are still needed to make sense of the results. Many really important decision still require a human in the loop.
And the top tweet is!
hmmmmmm.
Summing up — Cajun Style
PubTrawlr has had a ton of fun here in New Orleans. We’ve met some great people with great insights. That’s what we were after–the critical feedback that helps us put the research into practice. And that helps us to make a dent in the world.



